
这是一个创建于 221 天前的主题,其中的信息可能已经有所发展或是发生改变。
现在 AI 非常的流行, 各方面的应用都非常多。 比如在代码提示这个赛道上, 就有很多基于 AI 大模型的代码提示工具, 比如最著名的 GitHub Copilot , 再比如阿里的 通义灵码 , 还有今天要重点介绍的 Continue 。
与其它类似的 AI 智能代码提示工具不同,Continue 是开源的, 支持调用本地部署的大模型服务, 可以在企业内部甚至是安全隔离的局域网中运行, 并且提供了完善本地运行的文档。如果是私有代码库, 无法使用基于互联网的 AI 智能提示, 那么使用 Continue 搭建本地的智能代码提示, 也能达到比较好的效果 (当然不能与收费的 GitHub Copilot 媲美)。
Continue 介绍
以下功能介绍搬运自 Contine 的官方代码库。
Continue 是领先的开源代码助手。您可以连接任何模型和任何上下文,以在 VS Code 和 JetBrains 中构建自定义自动完成和聊天体验, 主要功能有:
更容易地理解代码片段 利用 AI 来解释代码段, 理解更容易。
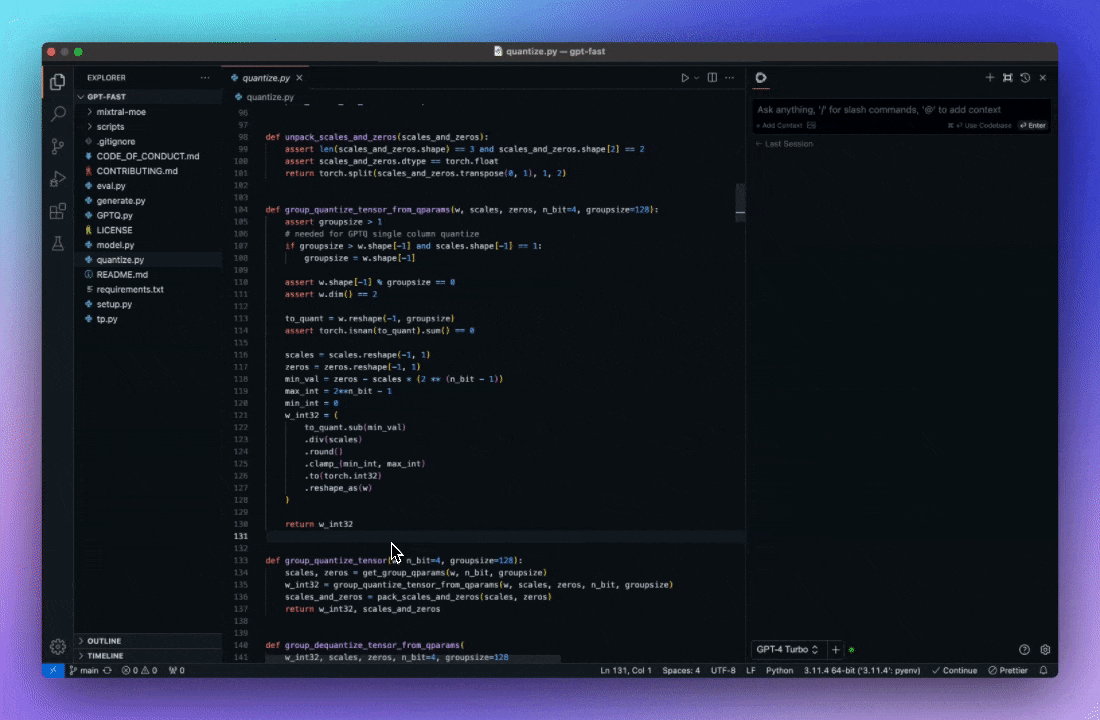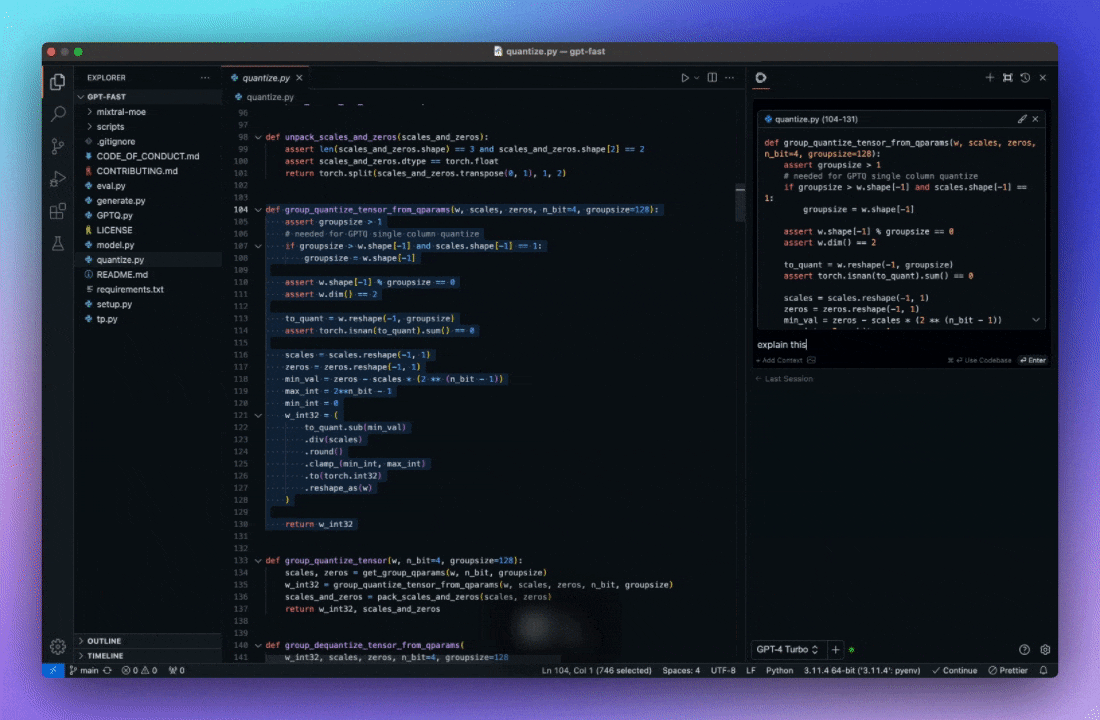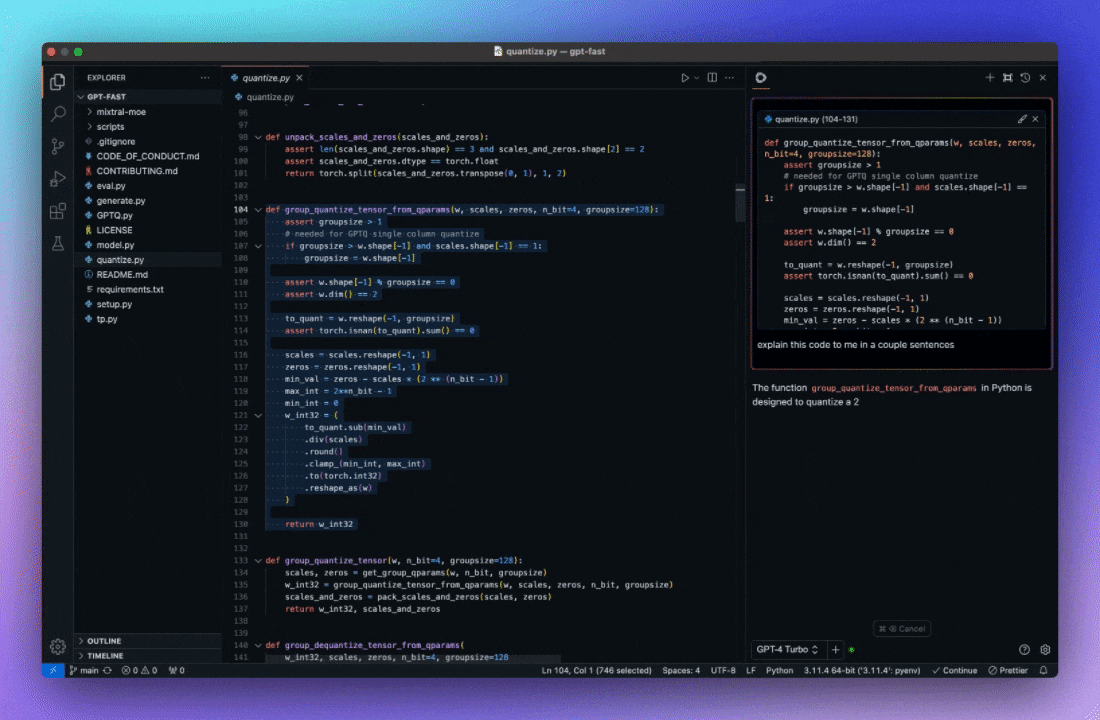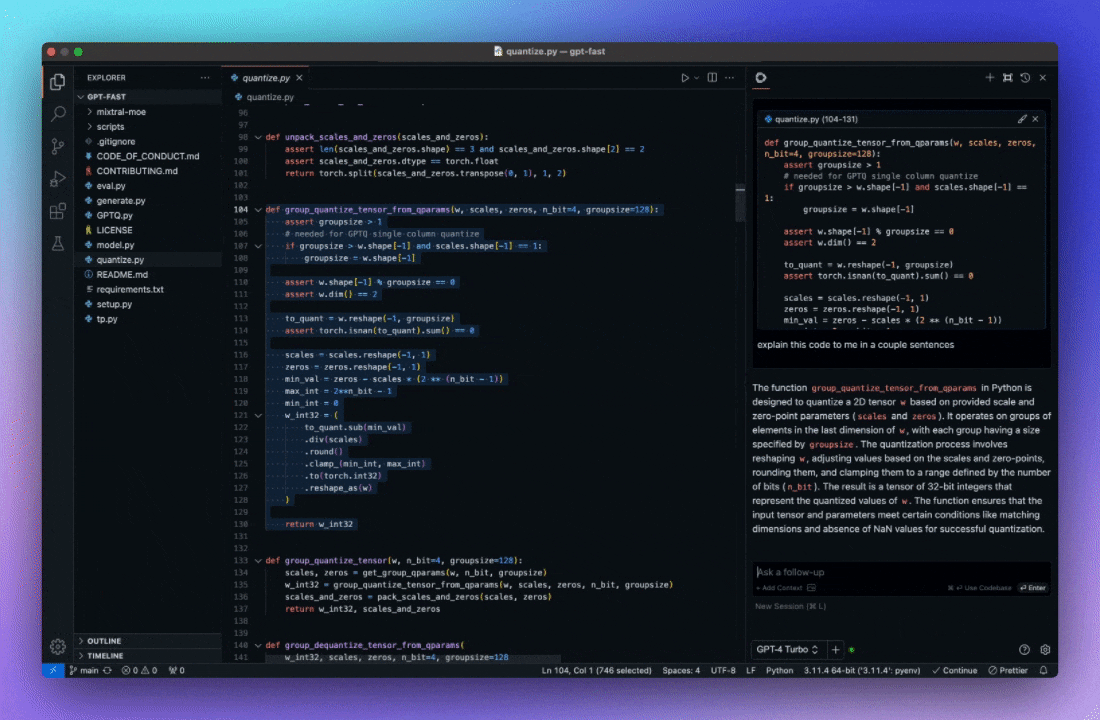
自动完成代码建议 利用 AI 理解代码上下文, 提供智能提示, 按 Tab 键自动补全。
随时重构 利用 AI 随时随地进行重构。

代码库问答 利用 AI 基于你的代码库进行问答。

快速文档上下文 快速使用框架的文档作为问答上下文。
模型选择
Continue 支持的模型非常多,具体可以看 选择模型 这篇文档, 根据这篇文档的建议, 需要运行两个模型实例:
-
问答: 建议使用 30B 以上参数的模型, 文档给的建议是
llama-3:- 算力充足
llama-3-70B; - 算力有限
llama-3-8B;
- 算力充足
-
代码提示: 建议使用 1 ~ 15B 参数即可, 文档给的建议是:
-
DeepSeek Coder:- 算力充足
deepseek-coder-v2:16b; - 算力有限
deepseek-coder:6.7b或者deepseek-coder:1.3b;
- 算力充足
-
StarCoder 2:- 算力充足
starcoder-2-7b; - 算力有限
starcoder-2-3b;
- 算力充足
-
经过实际测试, 建议的本地运行模型为:
- 问答模型, 选择
llama-3-8B或者同级别的模型就可以了, 一般不会达到运行llama-3-70B的硬件; - 代码提示模型, 如果你有一张不是太旧的独立显卡,比如 12G 显存的 3060 , 就可以流畅运行
starcoder-2-7b了, 安装了 cude 之后, 体验非常好; 如果没有, 则可以运行starcoder-2-3b, 也能体验到不错的效果;
如果算力有限, 优先运行代码提示模型, 因为这个使用的频率非常高, 在输入代码的同时, 会频繁的调用。 问答模型用的频率比较低, 因为需要用户主动提问。
llama.cpp
建议使用 llama.cpp 来运行大模型, 因为 llama.cpp 提供了非常灵活的选项, 对硬件支持也比较完善。 不管你是 Windows 系统还是 M1 芯片的 Mac 系统, 独立显卡还是集成显卡,甚至是 CPU 是否支持 AVX 指令, 都有特定的预编译版本, 根据自己电脑的硬件信息下载预编译的 llama.cpp 二进制文件即可。
当然也可以根据 llama.cpp 的 说明文档 , 拉取源代码, 根据自身的硬件信息进行编译, 以获得最佳性能。
关于 llama.cpp 的使用, 可以参考文章 在 Macbook M1 上运行 AI 大模型 LLAMA , 文中也介绍了如何下载并转换模型文件。
运行代码提示模型
下载 starcoder2-7b 或者 starcoder2-3b 作为代码提示模型, 使用 llama.cpp 的 llama-server 运行, 命令如下:
llama.cpp/llama-server --host 0.0.0.0 --port 28080 \
--threads 8 --parallel 1 --gpu-layers 999 \
--ctx-size 8192 --n-predict 1024 --defrag-thold 1 \
--model models/starcoder2-3b-q5_k_m.gguf
如果只是个人使用的话, 对于代码提示来说,3b 就足够了。 当然, 如果 GPU 算力充足的话, 也可以运行 7b 或者更高的模型。
经过测试,
starcoder提供的提示效果比deepseek-coder要好很多。
运行问答模型
下载 llama-3-8b 作为问答模型, 同样使用 llama.cpp 的 llama-server 运行, 命令如下:
llama.cpp/llama-server --host 0.0.0.0 --port 8080 \
--threads 8 --parallel 1 --gpu-layers 999 \
--ctx-size 8192 --n-predict 1024 --defrag-thold 1 \
--model models/meta-llama-3-8b-instruct.fp16.gguf
Continue 安装与配置
Continue 提供了 Jetbrains IDE 以及 VSCode 的插件, 以 VSCode 为例, 只需要在 VSCode 的扩展窗口中搜索 Continue.continue , 下载并安装即可。
安装之后, 可以直接跳过 Continue 的向导提示, 然后编辑它的配置文件 ~/.continue/config.json , 直接复制粘贴下面的 json 内容:
{
"models": [
{
"title": "LLaMA",
"provider": "llama.cpp",
"model": "llama3-8b",
"apiBase": "http://127.0.0.1:8080"
}
],
"tabAutocompleteModel": {
"title": "LLaMA",
"provider": "llama.cpp",
"model": "starcoder2-3b",
"apiBase": "http://127.0.0.1:28080"
},
"allowAnonymousTelemetry": false,
"embeddingsProvider": {
"provider": "transformers.js"
}
}
保存配置文件,Continue 插件会自动根据配置文件自动更新。
starcoder 模型支持 10 多种常见的开发语言, 因此只要配置好了 Continue 插件, 不管是写前端代码还是后端代码, 都可以享受 AI 带来的智能提示。
如果你的电脑 GPU 算力充足, 还可以把这个配置分享内网的小伙伴, 一起分享 AI 带来的便利。
总结
本地运行的优势就不依赖互联网网络, 几乎没有什么网络延时, 也不需要注册什么账户之类的操作, 没有任何敏感代码泄漏的风险。 主要是显卡的负载,CPU 负载不高, 所以也几乎感觉不到卡顿。
 |
1
beginor OP |
 |
2
Daffodil8564 221 天前
妙妙妙
|
 |
3
cinlen 221 天前
多谢分享。
大佬有试过在 mac m1 上 ollama + starcoder-2-3b 跑的效果吗 ? |
 |
4
augustheart 221 天前
本地模型……哎,优点就只是一个本地了
|
 |
5
noahlias 221 天前
这个出来好久了
|
 |
6
lithiumii 221 天前 via Android
continue + ollama + Gemma2 27b ,感觉还是很好的
|
 |
7
HelixG 221 天前
llama-3-70B 那个一张 4090 估计跑不动把
|
|
8
beginor OP @cinlen 我本地就是用 llama.cpp + starcoder2-3b-q5_k_m.gguf , 效果自我感觉还算可以。
另外,ollama 给的模型默认是 q4-0 量化版本,虽然可以一秒钟多几个 token , 但是质量明显不如 q5_k_m 量化版本的。 |
|
10
beginor OP @HelixG 70b 不是个人电脑能跑起来的, 代码提示这个至少要每秒中 20 ~ 30 个 token 才好用。 而且就代码提示这个功能来说, 官方给的建议也是 13b 以下的模型就足够了。
另外 JetBrains 也开始内置基于 LLM 的整行提示功能, 据说专门训练的 1b 模型,但是效果特别好。 |
 |
11
shuimugan 221 天前
还可以配置个 embedding 模型,把代码向量化到本地,方便 RAG 和补全出相似逻辑。向量化和代码片段数据保存在~/.continue/index/index.sqlite
附一份我本地的配置 ```json { "models": [ { "title": "Ollama", "provider": "ollama", "model": "codestral:22b-v0.1-q8_0", "apiBase": "http://10.6.6.240:11435/" } ], "customCommands": [ { "name": "test", "prompt": "{{{ input }}}\n\nWrite a comprehensive set of unit tests for the selected code. It should setup, run tests that check for correctness including important edge cases, and teardown. Ensure that the tests are complete and sophisticated. Give the tests just as chat output, don't edit any file.", "description": "Write unit tests for highlighted code" } ], "allowAnonymousTelemetry": false, "tabAutocompleteModel": { "title": "deepseek-coder-v2:16b-lite-base-q8_0", "apiBase": "http://10.6.6.240:11435", "provider": "ollama", "model": "deepseek-coder-v2:16b-lite-base-q8_0" }, "embeddingsProvider": { "provider": "ollama", "apiBase": "http://10.6.6.240:11435", "model": "mxbai-embed-large:latest" } } ``` |
|
12
beginor OP @shuimugan 我测试本地做 embeddings 非常慢, 所以就用了默认的 transformers.js 。 我觉得最重要的是 tabAutocompleteModel , 这个才是最能体验到的。
|
|
13
shuimugan 221 天前
@beginor 快和慢取决于带宽和算力,我测试 2080ti 22g / 7900xtx / m2 ultra 都很快,7B 模型 4bit 量化都超过 70token/s ,打开项目之后等几分钟插件做 embedding 入库就好了。
|
 |
14
1055619878 221 天前
有 Github Copilot 这个东西还有搭建的意义吗
|
 |
15
huangcjmail 221 天前
@shuimugan #11 这样做了 embedding 之后,可以哈 copilot 打一打吗。copilot 不知道有没有做类似 embedding 的逻辑
|
|
16
beginor OP @1055619878 当用不到 copilot 或者网络不顺畅或者不允许联网的私密网络的时候,就有意义了。 再说显卡闲着也是闲着,还不如用来提供点儿智能提示,就当打游戏了。
|
 |
17
xing7673 221 天前
@1055619878 copilot 现在变懒了很多
|
|
18
shuimugan 221 天前
@huangcjmail GitHub Copilot 也有 embedding 的逻辑,很显然的例子就是一段你删除了的代码,还可以补全出来,就是已经入库了做了向量化,在输入的时候做了相似搜索做上下文补全。
我 5 月份开始在 VSCode 禁用 GitHub Copilot 改用 Continue 来适应完全本地化 AI ,体验上来说很接近了,细节在于一些 if 语句判断还是 Copilot 严谨一些。但是大模型每个月都有新成果,在 14B 以下的尺寸卷疯了,这个尺寸很适合新出的 CPU 里那 NPU 和游戏显卡这种家用 24G 以下显存的设备推理。 |
 |
19
shylockhg 221 天前
为啥还是提示我登陆 github ?
|
 |
20
lee88688 220 天前 除了 Continue ,还推荐大家去尝试一下 cursor ,虽然是闭源产品但可以自定义 openai API ,可以对接本地 ollama 的 openai 兼容 API 或者链接外部的兼容 API 。我自己用 deepseek 的模型(主要是便宜🤣),体验真的可以的。
cursor 自带 embedding ,可以索引源代码和文档,这个功能我很喜欢,推荐大家尝试一下。 |
 |
21
dartabe 220 天前
感谢分享 感觉之后各行各业都会有类似的 AI 工具
毕竟很多公司都需要私有部署 |
 |
23
horizon 220 天前
我 M1 Pro 16G autocomplete 有点慢
还不如 codeium |
|
24
1055619878 220 天前
@lee88688 这玩意要 20 刀一个月 还不如买 copilot
|
|
25
lee88688 220 天前
@1055619878 花钱的可以用它提供的 GPT 的服务,但是可以自定义 openai 的 API 可以接 openrouter 或者 ollama 这种兼容 API 。
|
 |
27
skyqiao 201 天前
我 64 g 的 intel 的跑 deepseek2 那个模型补全差点把我卡死,让写个代码注释要好几分钟……
|
|
30
beginor OP ollama 底层也是调用 llama.cpp ,默认应该是没有显卡加速的, 打开 Activities 的 GPU 历史和 CPU 历史窗口看一下就知道了。
如果从源代码编译 llama.cpp 的话,可以自己看文档调参数看能不能启用 vulkan 或者 sycl 啥的。 CUDA 和 ROCm 都不支持 Mac ,所以肯定没有专用的硬件加速。 |
|
34
beginor OP @skyqiao Intel 的 Mac 应该没什么好的加速办法, 只能用 CPU 。 除非你装 Linux 或者 Windows , 还可以折腾下 vulkan 加速, 会比 CPU 快一些, 但是效果肯定不如 CUDA/ROCm/M1 。
|
|
35
beginor OP @skyqiao 关注一下 llama.cpp 的这个议题 https://github.com/ggerganov/llama.cpp/issues/8913
|
|
36
skyqiao 198 天前
@beginor #35 我看到一个 [Support intel igpus]( https://github.com/ollama/ollama/pull/5593) 不过还没合
|