iOS 开发实用技术导航
NSHipster 中文版
› http://nshipster.cn/
cocos2d 开源 2D 游戏引擎
› http://www.cocos2d-iphone.org/
CocoaPods
› http://cocoapods.org/
Google Analytics for Mobile 统计解决方案
› http://code.google.com/mobile/analytics/
WWDC
› https://developer.apple.com/wwdc/
Design Guides and Resources
› https://developer.apple.com/design/
Transcripts of WWDC sessions
› http://asciiwwdc.com
Cocoa with Love
› http://cocoawithlove.com/
Cocoa Dev Central
› http://cocoadevcentral.com/
NSHipster
› http://nshipster.com/
Style Guides
› Google Objective-C Style Guide
› NYTimes Objective-C Style Guide
Useful Tools and Services
› Charles Web Debugging Proxy
› Smore

这是一个创建于 2886 天前的主题,其中的信息可能已经有所发展或是发生改变。
正文
大家好,我是青云 QingCloud 系统工程师 Aspire 。今天我来和大家分享一下 QingStor SDK 以及自动化 SDK 生成工具 Snips 的开发经验。
今天交流的内容包括:
- QingStor SDK 简介
- QingStor SDK 的开发流程
- API Specification
- SDK 生成工具 Snips
- 场景化测试
- 使用 Snips 开发 QingStor Go SDK
1. QingStor SDK 简介
QingStor™ 对象存储为用户提供可无限扩展的通用数据存储服务,在 QingCloud Console (青云控制台)中可以直接创建、使用和管理对象存储 Bucket ,可以方便的上传下载文件。我们也提供了命令行工具(如 qingcloud-cli, qsctl) 来在各种场景下进行数据的存取。但是面对海量数据的操作时,图形化的界面和命令行工具是不够的。另外,我们的用户也需要在代码层面使用 SDK 或者直接请求 API 来接入 QingStor 对象存储。自上线以来我们就开放了一套标准、规范且简洁的 RESTful API ,以及一个 Python 的 SDK 。虽说 Python 的用户量非常大,但是显然只有这一种的 SDK 是无法满足用户需求的,再加上 QingStor 的 API 是遵循 RESTful 标准的,直接使用 API 来接入 QingStor 的成本也会高一些。(不过好在我们已在今年上半年兼容了 AWS S3 的 API ,所以用户也可以使用 S3 的 SDK 来接入 QingStor 。)
这里将 QingStor API 和 QingCloud IaaS 的 API 做个简单比较:
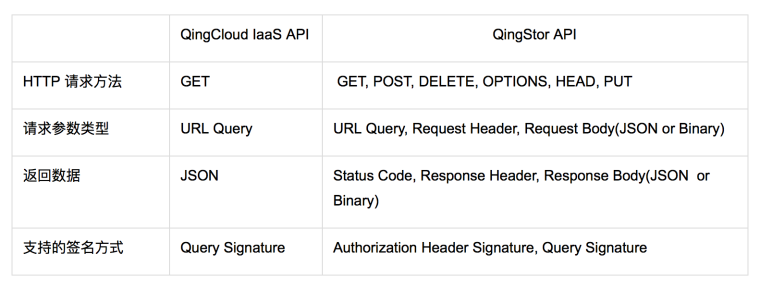
相比之下用户使用 API 来接入 QingStor 的难度会高一些,对 SDK 的需求也就更强烈。
目前 QingStor 提供了包括 Go 、 JavaScript 、 Ruby 、 PHP 、 Swift 、 Java 、 Python 在内 7 种语言的 SDK ,已经可以做到覆盖主流编程语言,而且有了 Snips 的帮助,开发者也能够在短时间内开发出另一种语言的 SDK 。
同时,此次我们将 QingCloud IaaS 和 QingStor 的 SDK 进行了拆分,例如 qingcloud-sdk-swift (尚未发布) 和 qingstor-sdk-swift 。这样做主要是考虑到移动端对空间比较敏感,所引入的第三方库越小越好,由于 QingCloud IaaS 目前开放的 API 数量是 QingStor 的三倍,将两者合并为一个包会造成空间的浪费,对于一个仅需要 QingStor 做为存储的 App 来讲,只引入 QingStor 的 SDK 就足够了。
QingStor SDK 的中文使用文档可以参考 https://docs.qingcloud.com/qingstor ;另外这些 SDK 也已开源在 GitHub ,可以访问 https://github.com/yunify 来获取,也欢迎大家给我们提 Issue 和 Pull Request 。
2. QingStor SDK 的开发流程
首先可以回顾一下我们 Python SDK 的开发方式,就是在 API 发生改变之后,手动增加 SDK 中与之对应部分的代码,这种做法效率不高,维护起来也让人头疼。
再加上 QingCloud IaaS 和 QingStor 共有两百多个开放 API ,并且不断有新的 API 伴随产品或功能上线,要做到 SDK 的实时跟进比较困难。而且现在只有一个 Python 的 SDK ,如果再加上其他语言的,每种语言都手动维护,会耗费工程师很多不必要的精力。还有一个问题比较麻烦,如果有用户对一些小众语言的 SDK 有需求,我们也没法立即进行支持,这点行业内基本都有类似的情况。
要解决这些问题,就需要换一种思路。我们可以看到,不同语言的 SDK 中都有很大一部分内容是用来进行 API 的描述(或者叫定义),而且这部分代码量是最大的,手写起来枯燥易错。所以我们采用了一种新的 SDK 的开发流程,使用标准的数据来生成代码,之后通过场景化的测试来进行验证,其中用到了我们自己写的一个代码生成工具━━ Snips 。
Snips 使用 API 的标准化描述和代码模版来生成各种语言 API 调用的那部分代码,除了生成出来的代码,还需要手动编写的代码,每种语言都不一样,不适合统一生成代码,比如错误处理,文件读写,网络请求等。这样做比起纯手工打造一个 SDK ,需要开发的代码量会小很多,开发效率能够得到很大的提升。
上面是利用 Snips 开发一种新的语言的 SDK 的示意图。下面具体说明一下。
新增一种语言的 SDK :
- 手写哪些错误处理、网络请求等相关的的代码
- 编写代码模版
- 使用 Snips 生成代码
- 通过场景化测试
- 发布
更新 SDK :
- 更新 API 描述
- 重新生成代码
- 通过场景化测试
- 发布
这里的 API 的描述我们是通过 Git Submodule 的形式引入到各个 SDK 项目中,这样如果是 API 的变更,完全不需要手动编写 SDK 的代码就可以做到 SDK 的更新。
下面会逐个讲一下 API 描述规范 ( API Specification )、 Snips 和 场景化测试( Scenario Based Testing )这几个部分,我们是怎么做的。
3. API Specification
要实现上述的流程,得先有 API 的描述,我们花了很长时间来确定使用怎样的 API 描述规范,也走了一些弯路。
起初我们自己制定了一个 API Specification 的 Schema :
- 这个 Schema 的目标是描述 HTTP API
- 每一个 API Specification 文件呈现一个 Service (如 QingCloud IaaS 或者 QingStor )
- Service 中可以有 SubService
- 同时 Service 和 SubService 中都包含 Metadata 、 Properties 、 Operations 、 Endpoint 等信息
- Operation 是具体的 API 请求,其中包含 Request 和 Response 的描述以及其他基本信息
- 定义了 boolean 、 integer 、 timestamp 、 binary 、 list 、 object 等几种基本的数据类型,及自定义的数据类型 CustomizedType, CustomizedType 可以出现多级引用
之后使用这套 Schema ,去描述了 QingStor 的 所有 API ,并且写了解析器,快速实现了从 API 描述生成 Go SDK 的代码。但是 Review 时我们发现这个自己定义的 Schema 还是太简陋,没有经过足够的数据进行验证,很多情况都没有考虑到,还有一些 Corner Case 也难以描述,并且这个 Schema 本身的校验效果也不理想。而且如果使用这套自己定义的 Schema 来描述 QingStor 和 QingCloud API ,无论是在内部使用还是开放出去,都是让人比较难以接受的,这种自立门户的做法也没有太大意义。
然后我们对比了几个目前可以用到的几个 API Specification 的规范,最后选择了 Swagger 。
Swagger 是一个描述 RESTful API 的规范, Swagger 具体的 Specification 大家可以访问它的网站来查看: http://swagger.io 。
今年的一月份 Swagger 更名为 OpenAPI Specification ,由 Linux 基金会赞助成立了 OpenAPI Initiative 来继续 OpenAPI Specification 的开发。在 Google 、 Microsoft 等大厂的支持下, Swagger 俨然已经成了业界标准,相关的生态和工具也已比较齐全,用它来作我们 API 的描述规范再合适不过,所以我们最终选择了 Swagger 来重新描述了 QingStor APIs ,并且实现了用 Swagger 描述规范来生成代码。
使用 Swagger 规范无疑是正确的,因为 Swagger 的工具和生态相对比较完善。以 Swagger Editor 为例,它是一个 API Specification 的 Web 编辑器,可以在编辑的同时提供代码补全、高亮和实时语法验证功能,感兴趣的朋友可以在 http://editor.swagger.io 体验一下。
Swagger 虽然发展的比较快,但并不是对所有 API 都友好。 QingCloud IaaS 的 API ,请求参数部分里会有数组( Array )和字典( Map )。例如 statics.n.router_static_name 、 statics.n.router_static_value 这种请求参数,用户实际提供的是一个由 Static 字典组成的数组,并且这个请求参数是位于 Request URL Query , SDK 会把数组和字典转换一下格式,构造出 statics.0.router_static_name=name&statics.0.router_static_value=value 这种形式的请求串。这样就会出现问题,在描述请求的时候需要定义数组和字典参数,由于 Swagger 的规范比较严格, Operation Parameter 不允许自定义类型出现,这时就只能将请求参数的描述放在 Request Body 里面来定义,这样就需要解析 Specification 的时候做一些特殊处理。
Swagger 标准也考虑到了 API 数量很多导致描述文件过长的情况,它支持使用 $ref 来引用其他文件,当然这个引用的功能其实是 JSON Reference 和 JSON Pointer 规范提供的,但是这里的 $ref ,只支持同一个文件内的引用,或者是引用某个 URL 链接。我们测试的解析器,包括 Swagger 官方的 swagger-codegen 都不支持文件间的引用,更不用提 Circle Reference 这种常用的情况了。不过这个问题我们在 Snips 中也解决掉了,可以看到我们的 QingStor API Specs 中的 API 描述是拆分成了很多文件的,具体内容等下 Snips 的部分会提到。
使用 Swagger API Specification 规范来描述 API ,其作用不仅仅可以用来生成代码,生成文档,更重要的是它的约束作用,它反过来可以规范 API 的开发和交付,进一步保证 QingCloud 的整体服务质量。对于 SDK 开发来讲则是一种 Data-Driven 的开发方式,这种思路可以让产出的各个 SDK 在功能上保持很强的一致性,不会出现某种语言的 SDK 缺失功能,或者是更新滞后,这种思路的优势也会随着更多产品和功能的上线变得越来越明显。
API Specification 文件本身也需要验证正确性,而使用 Swagger 标准可以轻而易举的使用 JSON Schema 来实现 Specification 数据的验证。
QingStor 的 API Specification 也放到了 GitHub ,这里是地址 https://github.com/yunify/qingstor-api-specs 。
4. 代码生成工具 Snips
接着讲讲代码生成工具,对于 Swagger 来讲,有官方的代码生成器 swagger-codegen ,还有其他的同类开源项目比如 go-swagger 。
它们虽说可以生成代码,但是生成出来的代码可控性和可读性都不高,并不能满足我们的需求,定制起来也比较麻烦。
例如采用 swagger-codegen 得 fork 过来,改它的 Java 代码,而且每增加一种语言的 SDK 基本上都要去增加对应的 Java 代码,这对于 Java SDK 之外的开发者来讲是非常不友好的。
除此之外还有很多其他细节上的问题,例如我们 API 的遗留问题,上面说到的 QingCloud IaaS 的请求参数不标准;例如 swagger-codegen 和 go-swagger 不支持文件引用的解析;生成出来的代码大小写控制不严格( acl 被转换成了 Acl ,而不是 ACL )等。
现有的代码生成器没有可以开箱即用的,都需要去进行不少的修改。但是去实现一个 Swagger 的解析器又太费时费力了,所以我们想到了一种折中的方案,使用开源的 Swagger 解析器来构建自己的生成器。
比对了几个开源项目之后,我们采用的解析器是 go-openapi/spec ( https://github.com/go-openapi/), 这个解析器的作者也是 go-swagger 的作者, go-swagger 是在这个解析器之上构建的。遗憾的是 go-openapi 也不支持文件引用,看到未来有支持文件引用功能的计划,不过不知道什么时候才会加上。于是我们简单熟悉了一下代码,之后提交了几个 PR 把这功能帮他们实现了,作者也欣然接受 “ With this PR go-swagger is the first library on go that fully supports json schema and ref resolving so very happy with it 👍”。
随后就有了代码生成工具 Snips ,它是一个命令行工具,很好地支持着我们的 SDK 开发,以 Go 语言 SDK 为例,包括模版在内,手写的代码大约 6 千行左右,而生成出来的代码已经达到了 2 万多行,开发效率得到了不小的提升。
关于模版, Snips 会从指定路径加载模版文件,模版目录下需要有一个 manifest 文件,可以是 JSON 或者 YAML 格式,这个文件指定了一些生成规则,例如指定该目录下模版文件的格式,输出文件名的命名风格是 CamelCase 还是 snake_case ;输出文件的扩展名和前后缀,可以参考 example 下的 manifest.yaml 来查看所有支持的规则。模版文件格式目前只支持一种,是 Go 语言的 template 。
与代码生成有关的简单逻辑是放在模版里去实现的,同时生成器也提供了一些内置函数可以在模版中使用,如大小写风格的转换、字符串替换、数据传递等,从而做到了生成器与某种语言无关,新增语言不需要去修改生成器的代码。上文提到的 acl 转换成 Acl 的问题,使用 Snips 提供的函数就可以正确转换,例如 {{snakeCase "acl"}} 会转换成 “ ACL ”。
关于多版本 API , Snips 也有解决方案。
通过 -n (--service-api-version) 参数来指定使用的 API 版本,然后将代码生成到不同的目录,例如 latest version 的代码在 service 目录,特定版本的代码可以在 service-2016-01-06 中,再根据语言的不同看是否还需要相应的调整。以 Go 语言为例,用户使用的时候 import 不同的路径的 service 即可切换不同版本的 API ,如 import "github.com/yunify/qingstor-sdk-go/service-2016-01-06"。
Snips 目前已经开源, GitHub 地址: https://github.com/yunify/snips 。目前是针对 QingCloud IaaS 和 QingStor API 的代码生成工具, Snips 的思路和其他的 Swagger 生成器的思路不太一样,未来也可能会做成一个通用的代码生成器。
5. 场景化测试
SDK 开发出来了,除了单元测试之外,还需要在线上生产环境进行测试,保证交付的 SDK 可正常工作,我们称之为服务测试( Service Test )。
服务测试中我们采用 Cucumber ( https://cucumber.io),它是一个 Behaviour-Driven Development (BDD) 工具。 Cucumber 会读取通过自然语言描述的测试场景和数据,然后结合不同的测试实现去验证是否通过。 Cucumber 可以被称作是一种测试方式,基本上每种语言都有它的实现。
举个例子:

获取一个 Object , Cucumber 描述是这样的:

Ruby 中对应的测试实现是这样的:

Cucumber 会检查代码场景执行过程中的数据是否满足预期,给出一个完成的测试结果
这样以使用者的角度来真实的测试 SDK ,并且可以让所有 SDK 的测试用例保持一致,在保证 SDK 质量的同时,也可以做到各种语言 SDK 功能的一致性。
QingStor SDK 的测试场景也放在了 GitHub : https://github.com/yunify/qingstor-sdk-test-scenarios
6. 使用 Snips 开发 QingStor Go SDK
上面讲了整套的 QingStor 的 SDK 开发流程,下面用 QingStor Go SDK 来举例说明一下。
qingstor-sdk-go https://github.com/yunify/qingstor-sdk-go
首先需要实现 SDK 最基础的部分,比如网络请求和签名处理、文件读写、错误处理等等,然后再使用 Snips 生成 API 相关的代码。
假设基础部分现在已经完成了,并且经过了单元测试。
接下来安装 Snips ,可以使用 go get -u github.com/yunify/snips 安装,或者直接访问 GitHub 下载编译好的二进制文件。
在代码仓库目录下以 git submodule 的形式引入 API Specification 和 Test Scenarios:
./specs/qingstor 引用 QingStor API specifications ./test/features 引用 QingStor 测试场景
然后便可编写代码模版,下图所示为 Go SDK 的模版文件:
具体的模板文件内容请见: https://github.com/yunify/qingstor-sdk-go/tree/master/template
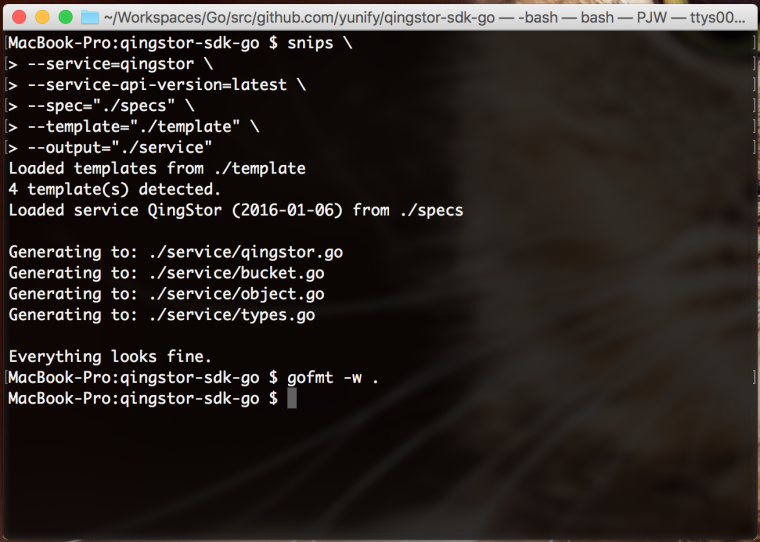
模板编写完成后,即可利用模版和 API Specifications 来生成代码。下图为生成代码的命令,生成完的代码有可能会难看,可以格式化一下代码,当然如果模版控制的严格,生成出来的代码足够漂亮,可以跳过格式化的步骤。
之后便可使用这些生成好的代码,实现测试场景,具体的代码请见这里: https://github.com/yunify/qingstor-sdk-go/tree/master/test
最后运行测试
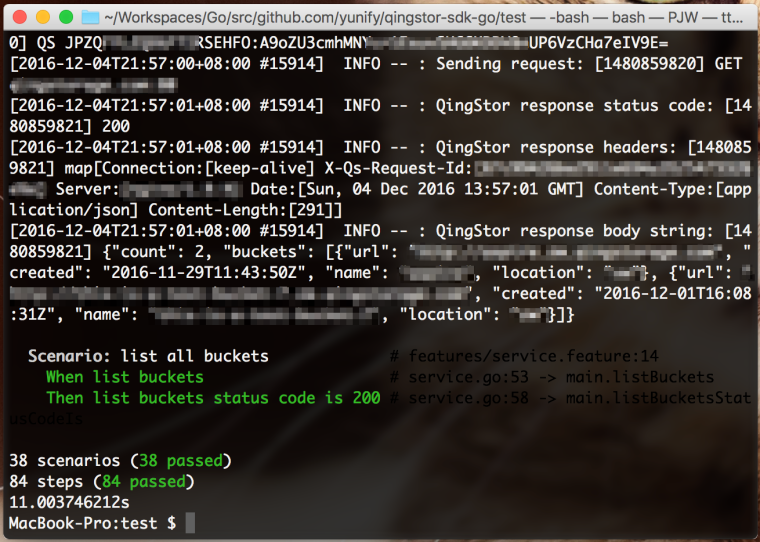
7. 开发者激励活动
目前 QingStor 已经提供了七种语言的 SDK (其中 Python SDK 的新版也会使用 Snips 来重新生成),覆盖了主流的编程语言,但还有一些编程语言的 SDK 我们没有来得及开发,为激励更多的开发者参与进来贡献其它语言的 SDK ,我们特此发起 QingStor SDK 大赛活动,报名地址请见: https://jinshuju.net/f/0MB6w6
 |
1
guyskk 2016-12-21 11:31:45 +08:00 via Android
干货满满,赞一个!
|